 Direto Notícias Imparcial, Transparente e Direto!
Direto Notícias Imparcial, Transparente e Direto!



Artigos Relacionados



Este post foi escrito por Uma Ramadoss, Especialista Principal SA, Serverless e Vinita Shadangi, Especialista Sênior SA, Serverless.
Hoje, o AWS Step Functions está expandindo os recursos do Distributed Map adicionando suporte ao formato JSON Lines (JSONL). O JSONL, um formato baseado em texto altamente eficiente, armazena dados estruturados como objetos JSON individuais separados por novas linhas, o que o torna particularmente adequado para o processamento de grandes conjuntos de dados.
Esse novo recurso permite que você processe uma grande coleção de itens armazenados no formato JSONL diretamente por meio do Distributed Map e, opcionalmente, exporte a saída do Distributed Map como arquivo JSONL. O aprimoramento também introduz suporte para formatos de arquivo delimitados adicionais, incluindo arquivos delimitados por ponto e vírgula e tabulação, oferecendo maior flexibilidade nas opções de fonte de dados. Além disso, novas transformações flexíveis de saída oferecem aos desenvolvedores mais controle sobre a formatação dos resultados, permitindo uma melhor integração com os processos posteriores para um tratamento eficiente dos dados.
Visão geral
O Distributed Map permite o processamento paralelo de dados em grande escala executando simultaneamente as mesmas etapas de processamento para milhões de entradas em um conjunto de dados na escala máxima de 10000. Isso é particularmente útil para casos de uso como processamento de folha de pagamento em grande escala, conversão de imagens, processamento de documentos e migrações de dados. Anteriormente, o conjunto de dados podia vir da entrada de um estado, arquivos JSON/CSV no S3 e de conjunto de objetos do S3. Com esse novo recurso, o conjunto de dados pode ser um arquivo JSONL no Amazon S3.
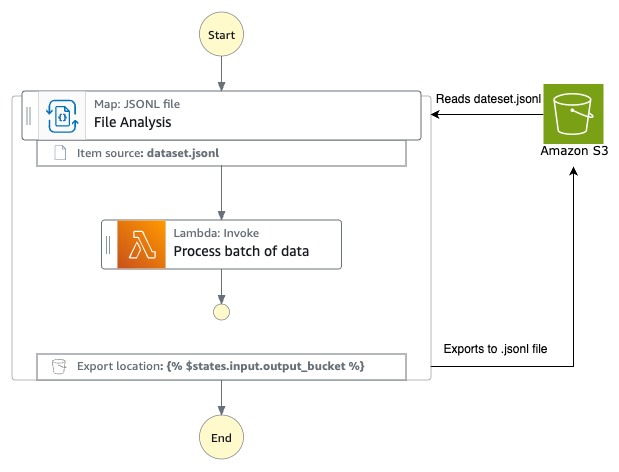
O fluxo de trabalho (workflow) do AWS Step Functions
Considere um exemplo de inferência em lote de GenAI de ponta a ponta usando o Amazon Bedrock. A inferência em lote ajuda você a processar um grande número de solicitações de forma eficiente, agrupando-as como uma única solicitação e armazenando os resultados em um bucket do S3. Como a entrada e a saída são tratadas como arquivos JSONL, este blog usa o cenário como exemplo para demonstrar os novos recursos do Distributed Map.
O diagrama abaixo mostra o fluxo de ponta a ponta
- O fluxo de trabalho do Step Functions (fluxo de trabalho de geração de entrada de inferência em lote) usa o Distributed Map para criar e agrupar solicitações de IA para uma coleção de dados de análise de produtos. O fluxo de trabalho então invoca a API de inferência em lote do Amazon Bedrock.
- O Amazon Bedrock armazena os resultados no S3 como arquivo JSONL quando a inferência em lote é concluída.
- Um evento criado por um objeto do S3 invoca o segundo fluxo de trabalho do Step Functions (fluxo de trabalho de processamento de saída de inferência em lote) que processa o arquivo JSONL e carrega os resultados em uma tabela do Amazon DynamoDB.

Fluxo de trabalho de inferência em lote
Apresentando novas transformações de saída por meio do fluxo de trabalho de geração de entrada por inferência em lote
O fluxo de trabalho de geração de entrada de inferência em lote processa os dados de revisão do produto no S3 usando o Distributed Map. O Distributed Map gera vários fluxos de trabalho secundários que geram solicitações de IA para análise de sentimentos de cada avaliação de produto e exporta os resultados dos fluxos de trabalho secundários para o S3 como um arquivo JSONL. O fluxo de trabalho chama a API de inferência em lote do Amazon Bedrock (CreateModelInvocationJob) com o arquivo JSONL como entrada após a conclusão do estado do Distributed Map. Como a API de inferência opera de forma assíncrona, o fluxo de trabalho é concluído imediatamente após receber uma resposta bem-sucedida da API.

Fluxo de trabalho de geração de entrada de inferência em lote
Cada fluxo de trabalho secundário recebe um lote de avaliações de produtos como uma matriz. Ele opera na matriz usando o estado Pass para criar uma matriz de solicitações de IA, uma para cada item. O estado Pass manipula a entrada usando expressões JSONATA, gera um RecordID exclusivo usando funções numéricas JSONATA e gera os resultados em um formato que o Amazon Bedrock espera.
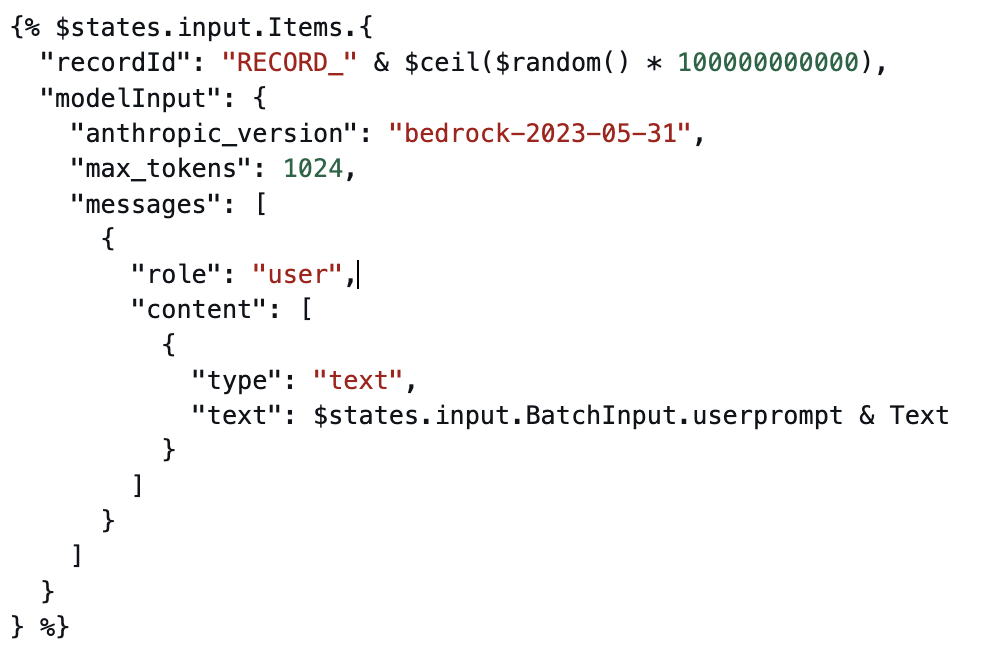
Transformação JSonata para gerar prompts
Depois que todos os fluxos de trabalho secundários estiverem concluídos, o Distributed Map usa as novas transformações de saída para exportar as saídas dos fluxos de trabalho secundários para o S3.
Usando as novas transformações de saída para exportar no formato JSONL
O Distributed Map agora oferece tratamento de saída mais flexível por meio de uma configuração opcional de gravador. Embora tradicionalmente exporte os resultados da execução do fluxo de trabalho secundário para três arquivos JSON separados (bem-sucedidos, com falha e pendentes), a nova configuração do gravador simplifica a saída e oferece suporte ao formato JSONL, além do formato JSON.
A opção de exportação anterior incluía detalhes abrangentes da execução — metadados, entradas e saídas do fluxo de trabalho secundário. A nova configuração permite que você simplifique a saída para incluir somente os resultados da execução do fluxo de trabalho secundário, que são valiosos para padrões de mapeamento/redução, em que a saída de um Distributed Map precisa ser alimentada diretamente em outro sem a necessidade de etapas adicionais de transformação.
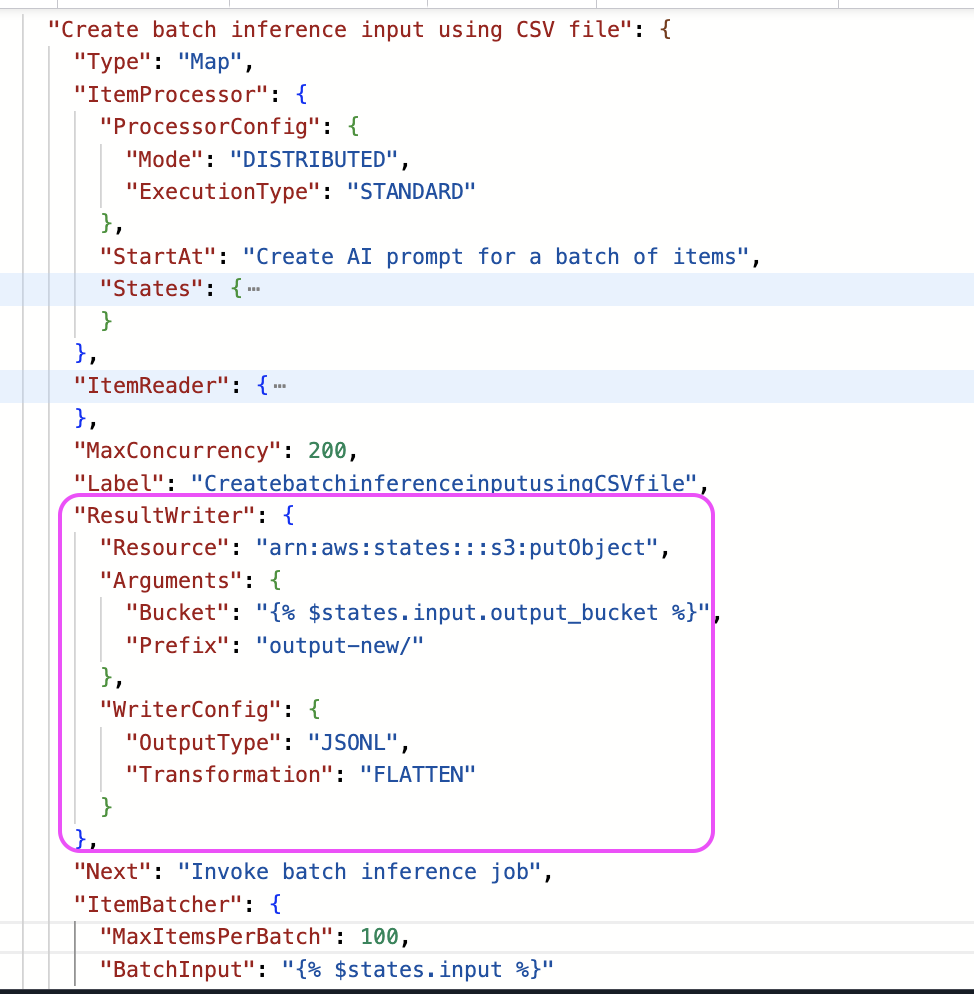
Configuração do gravador de saída para JSONL
A configuração do Writer também permite nivelar a matriz de saída. Quando um fluxo de trabalho secundário processa lotes da entrada, ele produz uma matriz de resultados que eventualmente se tornará uma matriz de matrizes quando o Distributed Map agregar as saídas de todos os fluxos de trabalho secundários. Com a nova transformação de saída chamada FLATTEN, você pode optar por nivelar a matriz sem código adicional.

Nivelamento da saída em JSONL
Apresentando o novo ItemReader para JSONL usando fluxo de trabalho de processamento de saída de inferência em lote
O segundo fluxo de trabalho processa a saída do trabalho de inferência em lote iniciando vários fluxos de trabalho secundários usando o Distributed Map. Cada fluxo de trabalho secundário processa lotes de itens, examinando-os em busca de objetos de erro e separando inferências bem-sucedidas de erros. Em seguida, o fluxo de trabalho carrega todas as inferências bem-sucedidas em uma tabela do DynamoDB enquanto envia os erros para uma fila de letras mortas para análise posterior.

Processando resultados de inferência
Usando o novo InputType para ler os resultados da inferência JSONL
O Distributed Map no fluxo de trabalho de processamento de resultados de inferência em lote usa o recém-suportado ItemReader-InputType, JSONL. Anteriormente, o InputType só aceitava CSV, JSON e MANIFEST, que é um arquivo de manifesto do S3 Inventory.

Lendo arquivo JSONL
Não há outra alteração na forma como o Distributed Map processa e compartilha dados com fluxos de trabalho secundários. O estado Pass no fluxo de trabalho secundário recebe lotes de itens do mapa e usa expressões JSonata para separar os erros dos itens bem-sucedidos.

Separando o processamento bem-sucedido dos erros
A seguir, mostramos a entrada recebida pelo estado Pass e a saída gerada pelo estado usando a expressão JSONATA acima.

Amostra de registros de processamento bem-sucedidos
Usando eventos S3 como método de junção entre os fluxos de trabalho
Quando o Amazon Bedrock conclui o trabalho de inferência em lote, ele armazena a saída no local do S3 especificado na solicitação da API. Uma regra do EventBridge aciona o fluxo de trabalho de processamento de resultados de inferência em lote usando notificações de eventos do S3. A regra procura o evento “Object Created” do bucket S3 especificado e um padrão curinga para a extensão de arquivo JSONL. Quando a regra corresponde ao evento de entrada, ela aciona o fluxo de trabalho.

Regra do EventBridge
Você pode detectar falhas em trabalhos de inferência em lote configurando as regras do EventBridge que escutam os eventos de status do Amazon Bedrock. Como os trabalhos com falha não criam arquivos de saída no S3, o monitoramento direto dos eventos de status garante que você detecte e resolva as falhas do trabalho.
Principais considerações
- As novas transformações de saída não alteram as informações no arquivo de resultados da execução FAILED para ajudá-lo a analisar os motivos das falhas. Para saber mais sobre as configurações de transformação de saída, acesse a documentação.
- O novo modo de transformação FLATTEN, COMPACT armazena somente a saída dos resultados da execução. Para inspecionar os resultados para verificação de fatos ou solução de problemas, use a transformação padrão.
- Como prática recomendada, ao implementar alterações no código, é recomendável usar o recurso de controle de versão e aliasing para a implantação gradual das alterações na produção.
- Ao usar o Distributed Map, há uma opção para configurar o fluxo de trabalho secundário como Padrão ou Expresso. O Express é a opção recomendada se cada iteração (fluxo de trabalho secundário) puder ser concluída em 5 minutos, e o agrupamento de itens ajudará a otimizar os custos. Para saber mais sobre otimizações para o Distributed Map, visite o workshop.
Conclusão
O Step Functions Distributed Map é um recurso poderoso que permite aos desenvolvedores criar soluções de processamento de dados em grande escala com facilidade, eliminando preocupações sobre aspectos operacionais e desafios de software, como lotes, simultaneidade e tratamento de falhas. A adição do suporte JSONL para entrada e saída expande os recursos da carga de trabalho e minimiza o esforço adicional por meio de transformações ao desserializar e nivelar a saída de forma nativa. Este blog demonstrou os recursos do novo recurso por meio de um exemplo prático de criação de aplicativos de processamento de dados em grande escala usando o Distributed Map.
Para obter mais informações sobre o Distributed Map e como usá-lo com arquivos JSONL, consulte o guia do usuário.
Para explorar amostras generativas de IA com o Step Functions, visite o repositório GitiHub.
Para expandir seu conhecimento sem servidor, visite Serverless Land.
Este blog é uma tradução do conteúdo original em inglês (link aqui).
Biografia dos Autores
 | Uma Ramadoss, Principal Specialist SA, Serverless |
 | Vinita Shadang, Senior Specialist, Serverless |
Biografia do Tradutor
 | Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Biografia do Revisor
 | Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |
